Помощник
|
|
|
|
|
|
 Сообщение сайта
Сообщение сайта


|
 AParser_Support
AParser_Support
|
 5.4.2018, 12:01;
Ответить: AParser_Support 5.4.2018, 12:01;
Ответить: AParser_Support
Сообщение
#182
|
 Бывалый  Группа: User Сообщений: 281 Регистрация: 3.6.2013 Поблагодарили: 13 раз Репутация:  13 13 
|
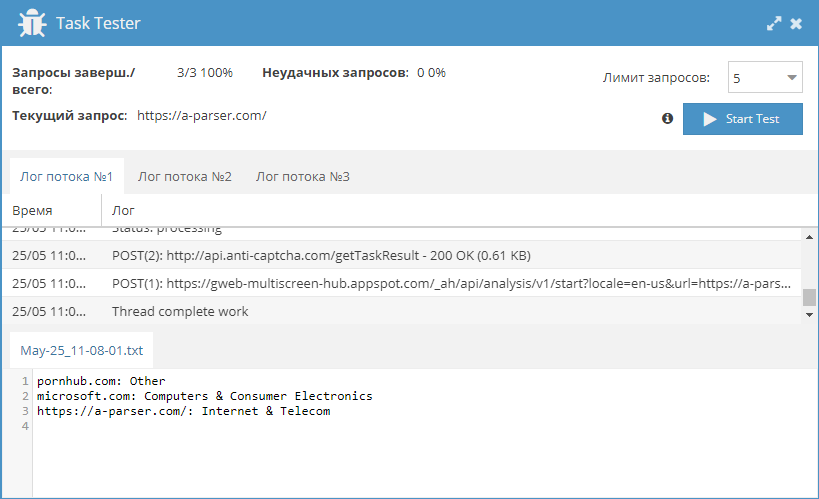
Видео урок: Создание JS парсеров. Работа с CAPTCHA
Третье видео в цикле уроков по созданию JavaScript парсеров. Здесь рассказано о том, как написать JS парсер, в котором будет поддержка антигейта для разгадывания каптч на страницах. В уроке рассмотрено:
Статья и готовый парсер: https://a-parser.com/resources/257/ Оставляйте комментарии и подписывайтесь на наш канал на YouTube! -------------------- |
 |


|
|
AParser_Support
|
26.4.2018, 12:32;
Ответить: AParser_Support
Сообщение
#184
|
|
Бывалый Группа: User Сообщений: 281 Регистрация: 3.6.2013 Поблагодарили: 13 раз Репутация: 13
|
Сборник статей #3: пагинация, переменные и БД SQLite
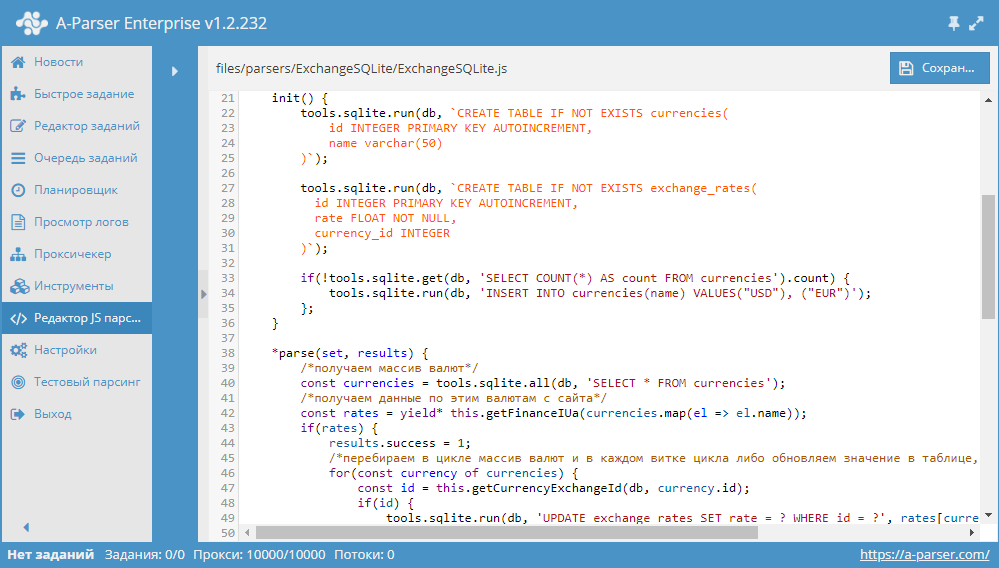
В этом сборнике статей мы рассмотрим все возможные варианты решения задачи прохода по пагинации на сайтах, очень детально изучим работу с переменными в JavaScript парсерах, а также попробуем работать с базами данных SQLite на примере парсера курсов валют. Поехали! Обзор вариантов прохода по пагинации В A-Parser существует несколько способов, с помощью которых можно реализовать проход по пагинации. В связи с их разнообразием, становится актуальным вопрос выбора нужного алгоритма, который позволит максимально эффективно переходить по страницам в процессе парсинга. В этой статье мы постараемся разобраться с каждым из способов максимально подробно. Также будут показаны реальные примеры и даны рекомендации по оптимизации многостраничного парсинга. Статья - по ссылке выше. 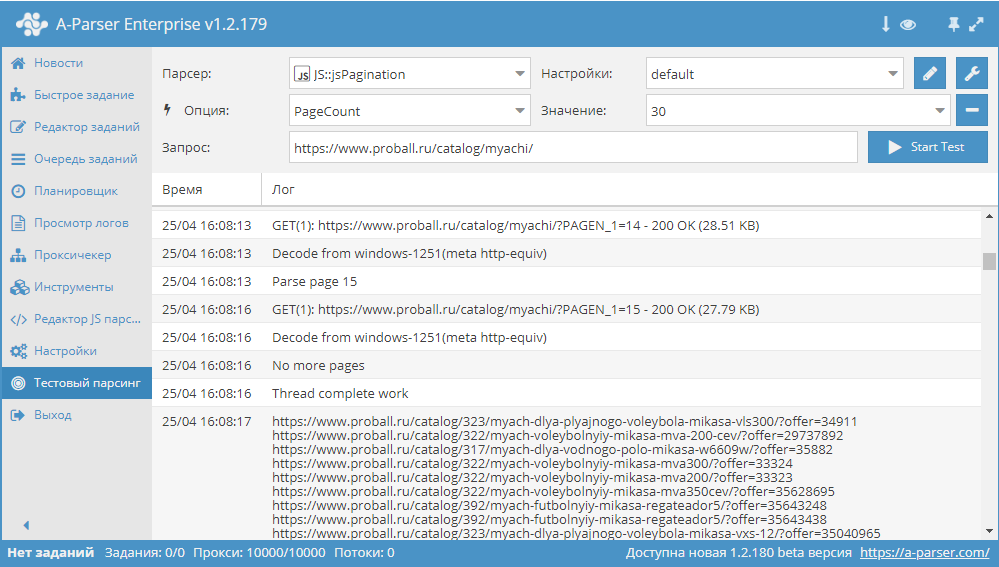 Переменные в парсерах JavaScript JS парсеры в А-Парсере появились уже около года назад. Благодаря им стало возможным решать очень сложные задачи по парсингу, реализовывая практически любую логику. В этой статье мы максимально подробно изучим работу с разными типами переменных, а также узнаем, как можно оптимизировать работу сложных парсеров. Все это - в статье по ссылке выше. 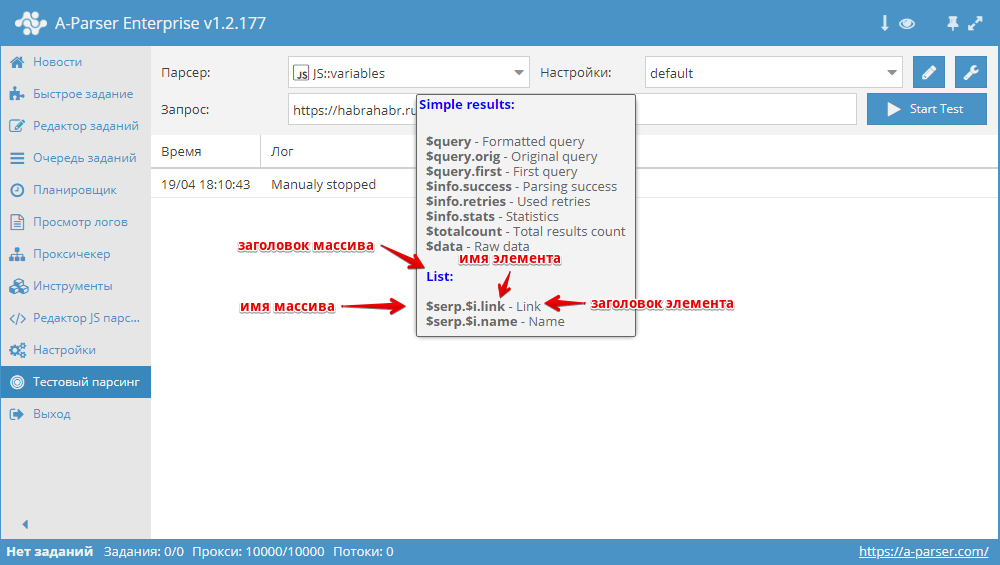 Разработка JS парсера с сохранением результата в SQLite Начиная с версии 1.2.152 в A-Parser появилась возможность работать с БД SQLite. В данной статье мы рассмотрим разработку JavaScript парсера, который будет парсить курсы валют из сайта finance.i.ua и сохранять их в БД. В результате получится парсер, в котором продемонстрированы основные операции с базами данных. Подробности, а также готовый парсер - по ссылке выше. 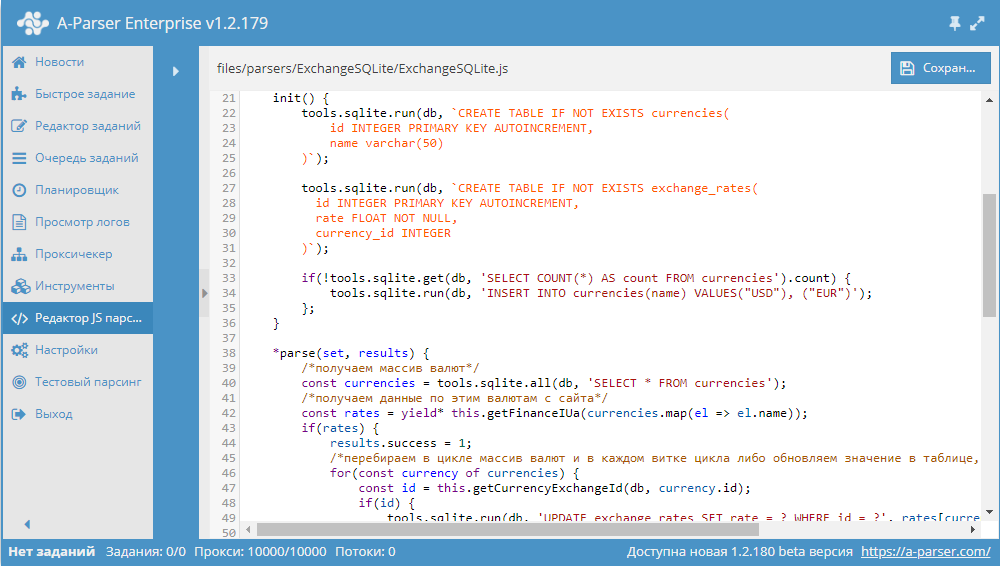 Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки  ) - отписывайтесь здесь. ) - отписывайтесь здесь.Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter. Предыдущие сборники статей -------------------- |
|
|
|
|
AParser_Support
|
7.5.2018, 13:32;
Ответить: AParser_Support
Сообщение
#185
|
|
Бывалый Группа: User Сообщений: 281 Регистрация: 3.6.2013 Поблагодарили: 13 раз Репутация: 13
|
1.2.185 - увеличение скорости в SE::Google::Modern, новые возможности Net:: DNS, множество улучшений
 Улучшения
Исправления в связи с изменениями в выдаче
Исправления
-------------------- |
|
|
|
|
AParser_Support
|
17.5.2018, 11:59;
Ответить: AParser_Support
Сообщение
#186
|
|
Бывалый Группа: User Сообщений: 281 Регистрация: 3.6.2013 Поблагодарили: 13 раз Репутация: 13
|
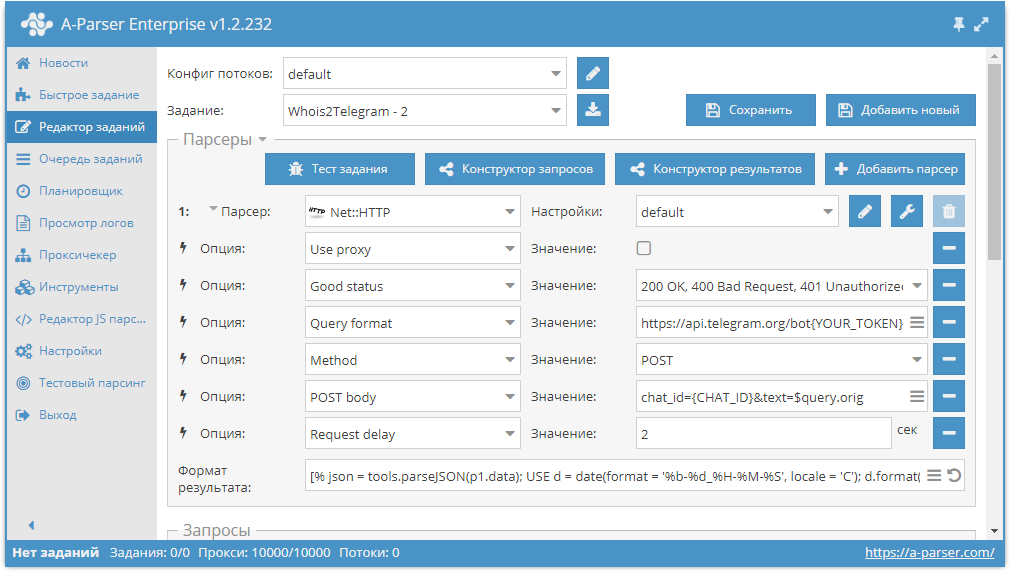
Разгадывание рекаптч в JS парсере
Очередное видео в цикле уроков по созданию JavaScript парсеров. Здесь показано, как реализовать разгадывание рекаптч в JS парсере.  В уроке рассмотрено:
Ссылки:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube! -------------------- |
|
|
|
|
effovenon
|
7.6.2018, 2:26;
Ответить: effovenon
Сообщение
#188
|
 Участник Группа: User Сообщений: 178 Регистрация: 14.6.2014 Поблагодарили: 36 раз Репутация: 10
|
Спасибо за частые обновление! Знаю два софта, которые так часто обновляются. Это кейколлектор и А -парсер!
Занимаюсь прогонами, по этому базы нужно постоянно новые, с Вашим супер парсером, базу в 1 лям, могу напарсить за пол дня. Также, пол года назад, взяла A-Parser Enterprise. Апи работает шикарно! Через апи, на зенке, на удаленке парсю базы, и сразу обрабатываю, что очень экономит время! Спасибо большое Forbidden, за Ваш потрясающий софт, которым реально, аналогов просто нет! -------------------- |
|
|
|
|
AParser_Support
|
11.6.2018, 12:06;
Ответить: AParser_Support
Сообщение
#189
|
|
Бывалый Группа: User Сообщений: 281 Регистрация: 3.6.2013 Поблагодарили: 13 раз Репутация: 13
|
1.2.216 - улучшения в SE::Google::Modern и JS парсерах, а также множество других
 Улучшения
Исправления в связи с изменениями в выдаче
Исправления
effovenon, Очень приятно слышать позитивные отзывы. Будем продолжать в том же направлении! -------------------- |
|
|
|
|
Remakes
|
11.6.2018, 14:29;
Ответить: Remakes
Сообщение
#190
|
|
Новичок Группа: User Сообщений: 20 Регистрация: 9.6.2018 Поблагодарили: 1 раз Репутация: 1
|
Являюсь пользователем данной программы, работает отлично, рекомендую всем кто работает с большими базами ...
|
|
|
|

|

![]() Похожие темы
Похожие темы
| Тема | Ответов | Автор | Просмотров | Последний ответ | |
|---|---|---|---|---|---|
 |
Большие базы Semrush кейвордов по разным тематикам! Много кейвордов с трафиком и без конкуренции! Volume, KD, CPC | 23 | Krok | 6895 | Сегодня, 5:58 автор: Krok |
|
Базы Youtube кейвордов с данными по конкуренции и Volume | 6 | Krok | 1590 | 23.4.2024, 5:43 автор: Krok |
|
Бесплатный парсер бот в Телеграм - [Parser Pro] | 5 | Parser_Pro | 3354 | 27.1.2024, 16:12 автор: Parser_Pro |
|
Дайте бесплатного контента! :) | 2 | Tia2 | 1001 | 22.12.2023, 18:53 автор: zyzy |
 |
Занимаюсь добычей качественного контента из Вебархива. Опыт уже более трех лет Предоставляю только качественный, читабельный контент. |
62 | kuz999 | 38121 | 27.7.2023, 13:55 автор: kuz999 |

|
Текстовая версия | Сейчас: 25.4.2024, 10:56 |